一、主题式网络爬虫设计方案(15分)

1.主题式网络爬虫名称 爬取新浪网热搜
2.主题式网络爬虫爬取的内容与数据特征分析 爬取新浪网热搜排行榜、热度
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
本案例使用requests库获取网页数据,使用BeautifulSoup库解析页面内容,再使用pandas库把爬取的数据输出,并对数据可视化,最后进行小结;技术难点:爬取有用的数据,将有碍分析的数据剔除,回归直线。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
页面内容如下,本方案要爬取的是表格中的内容。
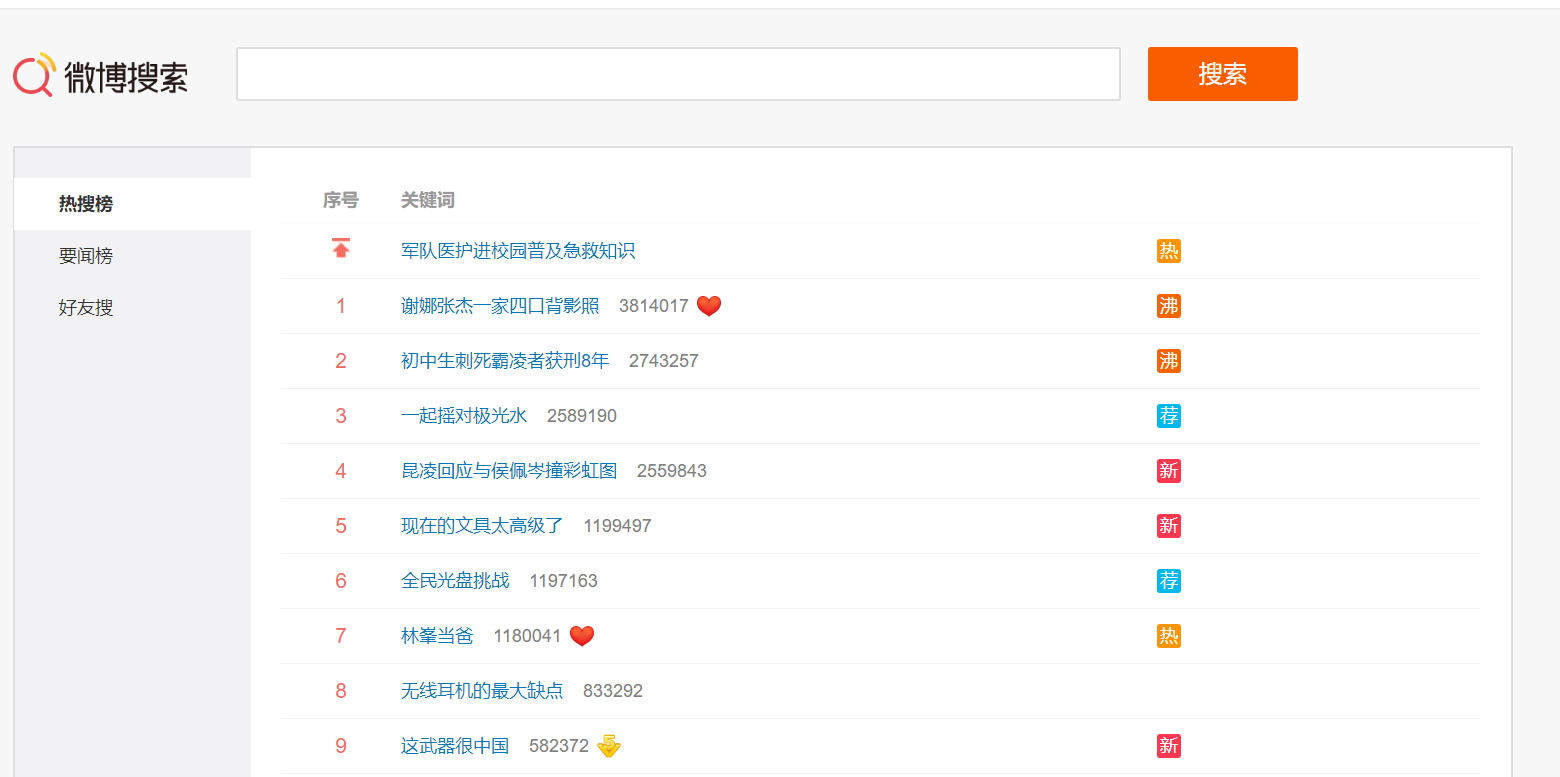
2.Htmls页面解析
通过F12,对页面进行检查,查看我们所需要爬取内容的相关代码。
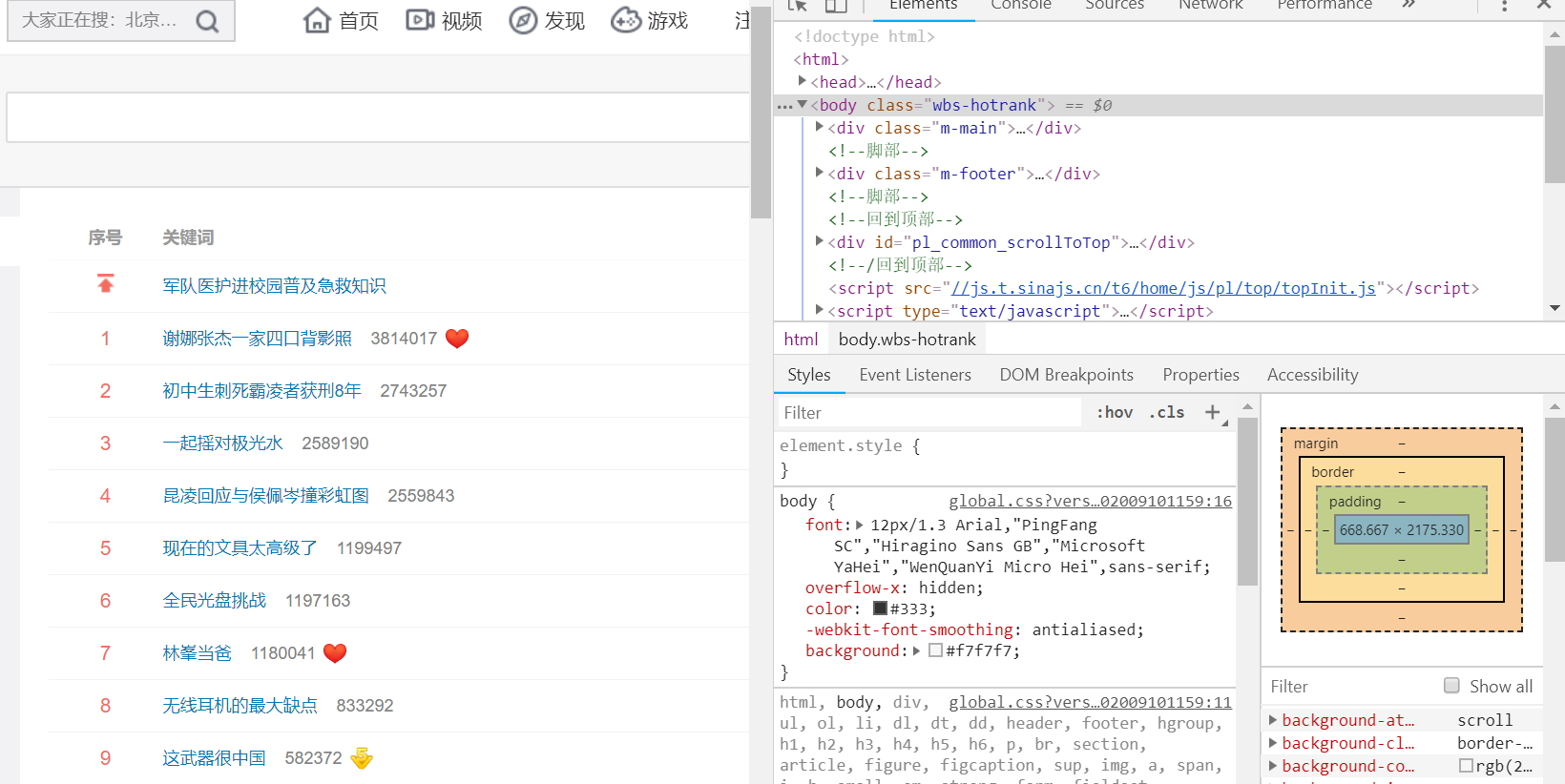
三、网络爬虫程序设计(60分)
1.数据爬取与采集(20)
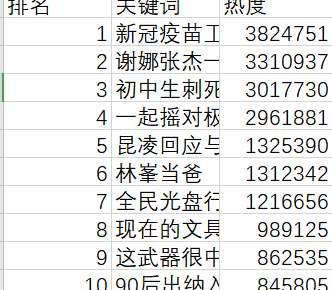
爬取的数据



提取前十存入Excel
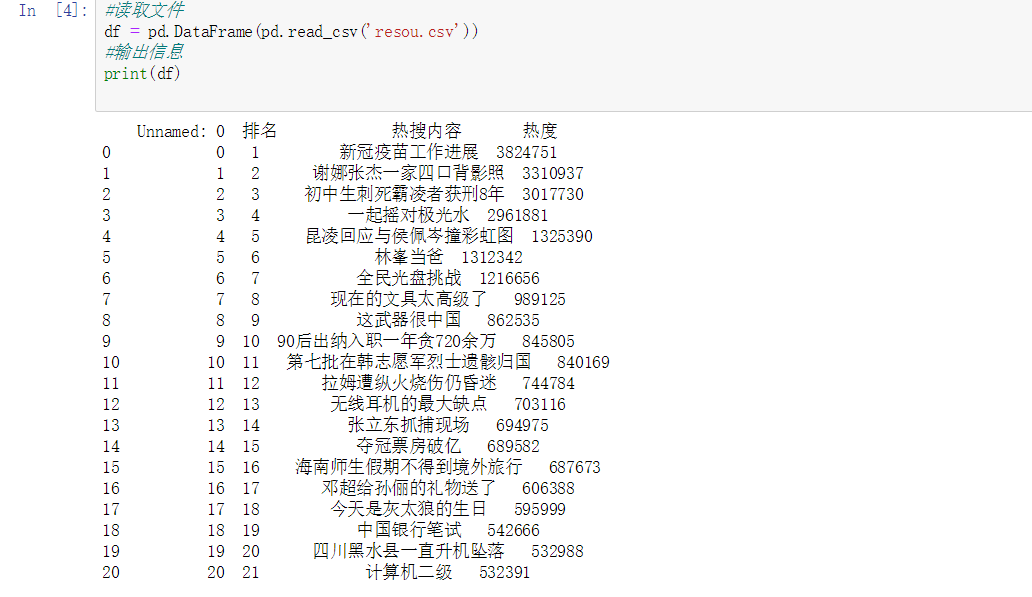
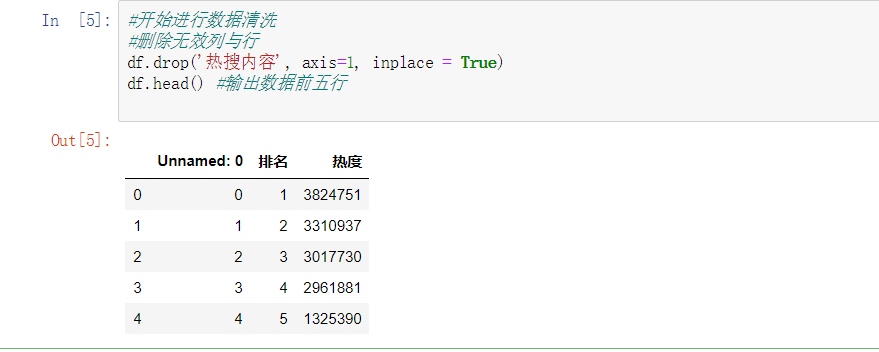
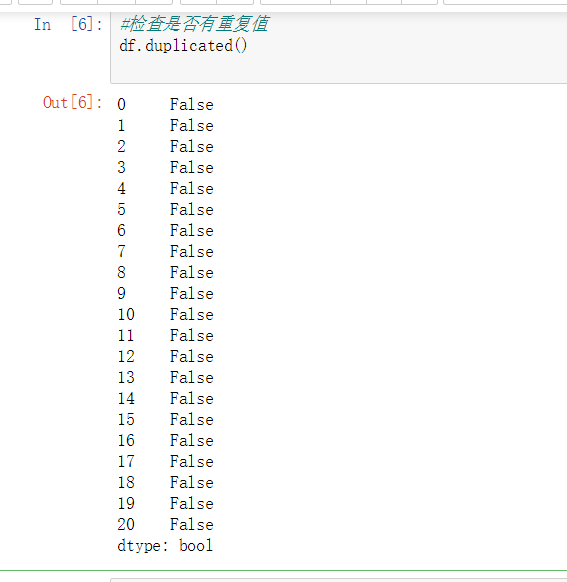
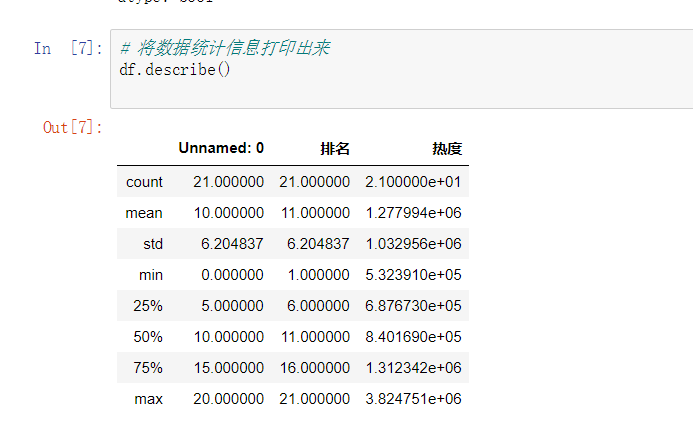
2.对数据进行清洗和处理(10)
3.数据分析与可视化(15)






一元二次回归方程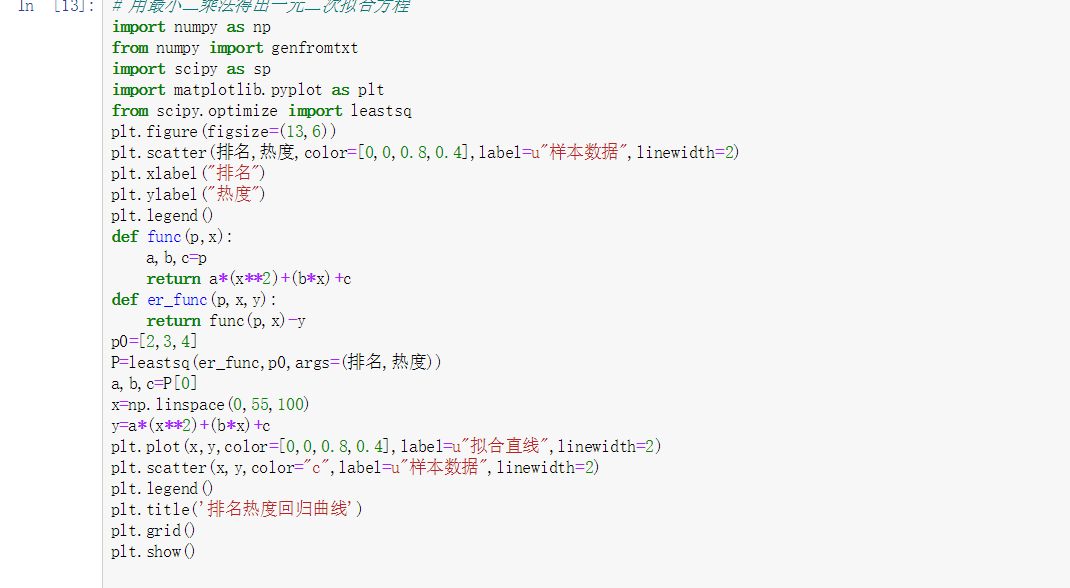

完整代码

四、结论(10分)
1.经过对主题数据的分析与可视化, 可以得到哪些结论?
经过对数据的分析,可以观察到热搜的排名及热度,数据的可视化使得爬取的数据更加的清晰,通过对数据的分析使得操作更加熟练。
以上就是本篇文章【爬取新浪微博热搜榜】的全部内容了,欢迎阅览 ! 文章地址:http://dfvalve.xrbh.cn/quote/293.html 行业 资讯 企业新闻 行情 企业黄页 同类资讯 网站地图 返回首页 迅博思语资讯移动站 http://keant.xrbh.cn/ , 查看更多