实时检索分析平台(Hermes)是腾讯数据平台部为大数据分析业务提供一套实时的、多维的、交互式的查询、统计、分析系统,为各个产品在大数据的统计分析方面提供完整的解决方案,让万级维度、千亿级数据下的秒级统计分析变为现实。

Hermes实时检索分析场景

1、营销分析

作为营销人员,首先需要确认营销目标群体,并且在什么时间以什么形式,开展什么营销活动效果最好?首先需要找到目标群体号码包,通过指定条件(如性别、年龄、兴趣爱好,曾经有过类似行为)提取号码包;通过大数据分析,得知在某个时间段参与人数较多,哪种类型的活动效果更受欢迎,目标用户群体有哪些共同特征。掌握这些,你的营销活动效果更加好;
2、系统运营分析

一个产品的后台有着成千上万个接口,各个接口的性能指标是开发人员、运维人员特别关注的,每个接口可能都有不同的版本号,要判断系统是否稳定不是某个时间点的数据能体现出来的,需要对比分析历史数据才能发现潜在的问题。也许问题只出现在某个接口的某个版本中,并且只有特定版本的接口发送到特定接口才会重现这种问题,开发人员除了大量的日志外,没有很直观的途径能指导开发人员有针对性的定位问题。如果对这些性能数据进行实时的多维度的数据分析,只需要根据问题的表象分析对应的版本号、对应的接口就能查看到对应的性能数据指标,从而快速缩小问题发生范围,为问题定位提供高效的解决途径。此外不同版本性能的周期性对比、新版本上线性能跟踪等都是系统运营分析所不可或缺的。
3、趋势分析
当面对每天几百几千万的数据,mysql等传统的数据库能帮你搞定,但是当你要分析周期性数据, 比如最近三十天,这个数据量,也许你没疯mysql就已经”疯”了。当要分析的数据按月按年计算呢?肯定很多人考虑hadoop,没错,它是能帮你解决这么大的数据量的分析工作,但是hadoop不能让你即查即所见?一个分析人员效率高低,很多时候取决于工具的时效性,这直接影响着分析人员、运营人员的分析思维连贯性。
4、探索性分析

很多分析人员分析的目的是验证性的、是探索性的,在不断的调整验证自己的猜想最终发掘有效信息从而为产品发展找到决策性数据依据。假设你有10亿的数据量,字段数达到上百个,分析人员任何一个YY分析需求都有可能是这上百个字段其中的组合,假设我们从中取5个字段做组合分析,100个字段中取五个字段的组合数能达到75287520,每次查询就算耗时500毫秒,预处理也要430多天。可见,任意组合的查询分析、即查即所见的多维组合分析是探索性分析必需具备的”硬件”条件。
5、全文检索
很多场景需要根据关键字对数据进行实时检索服务, 目前我们支持数据的实时接入,也支持数据的批量导入。除此高效的毫秒级检索分析服务外,我们还支持用户对结果集的导出。
Hermes设计概要
1、架构描述

系统核心进程均采用分散化设计,根据业务发展需求,可随意扩缩容机器;
周期性数据直接通过tdw处理落地到分布式文件系统;
实时数据加载采用先落地本地磁盘,最终落地到分布式文件系统,最终都由调度进程分发到计算层;
2、分析引擎设计
基于单个实例数据的分析处理,datasource主要包含两类数据:用户导入的数据(位图文件)以及源数据(索引文件),内核主要根据用户请求逻辑处理索引文件以及位图文件

3、内核设计
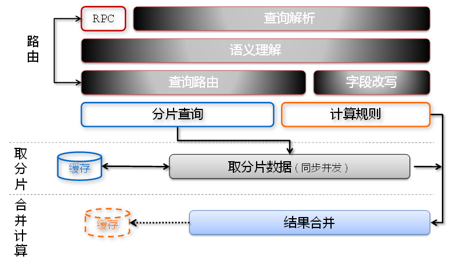
整个数据对应多份,按照不同规则均匀分布在各个分析实例中,数据的merge服务在其中的一个分片中进行,每次请求将根据机器负载情况选择负载轻的作为merge服务
4、存储设计
通过对数据结构的重新组织,结合分析系统的特点,实现嵌套列存储,充分避开随机读,采用块读取+位图计算大幅度降低耗时弊病,使大数据的统计分析计算耗时缩短至秒级;
在词条文件中采用字典排序,并在此基础上实现前缀压缩;
在序列文件中采用递增排序,并对序列号采用可变长类型,有效压缩存储空间,便于计算位图的构建;
5、存储格式
存储格式主要包含四类文件
meta文件: 描述表结构,内存文件;
词条文件: 描述各个字段的词条集信息,磁盘文件;
词条索引文件: 词条文件的跳表映射文件,用于加速定位目标词条,内存文件;
序列号文件: 词条出现的序列集,采用可变长类型存储序列号, 每个词条对应的序列号集又包含跳表映射数据块,用于加速具体序列的定位,磁盘文件;

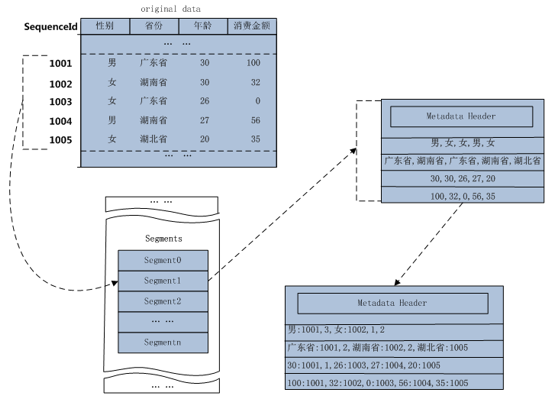
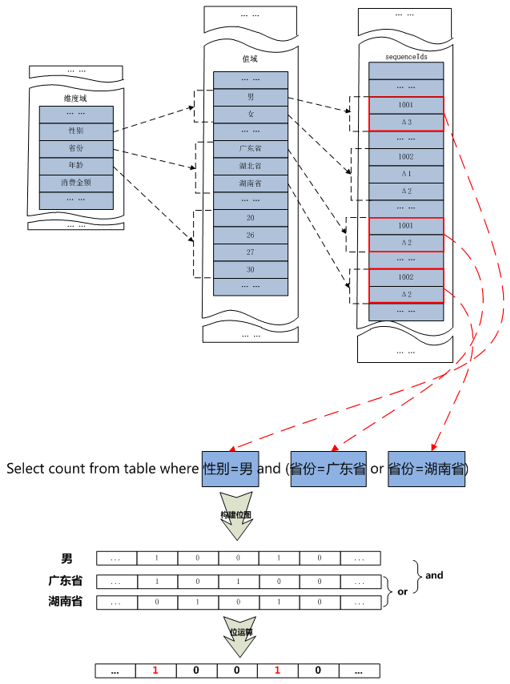
存储分析过程示例:
6、流程设计

数据容灾:根据业务特点,采用分布式文件系统或冗余存储解决。
进程容灾:根据进程的特殊性,采用Master-Slave或者冗余解决进程容灾问题。
数据加载支持实时和周期性两种方式。
7、数据接入

实时数据服务:提供数据实时接入,保证数据即入即所查。
历史数据服务:提供T+1数据以及数据补录等场景,保证数据有效周期。
Hermes与开源的Solr、ElasticSearch的不同
1、Hermes与Solr,ES定位不同
Solr、ES:偏重于为小规模的数据提供全文检索服务;Hermes:则更倾向于为大规模的数据仓库提供索引支持,为大规模数据仓库提供即席分析的解决方案,并降低数据仓库的成本,Hermes数据量更“大”。
Solr、ES的使用特点如下:
源自搜索引擎,侧重搜索与全文检索。
数据规模从几百万到千万不等,数据量过亿的集群特别少。有可能存在个别系统数据量过亿,但这并不是普遍现象(就像Oracle的表里的数据规模有可能超过Hive里一样,但需要小型机)。
Hermes:的使用特点如下:
一个基于大索引技术的海量数据实时检索分析平台。侧重数据分析。
数据规模从几亿到万亿不等。最小的表也是千万级别。在腾讯17 台TS5机器,就可以处理每天450亿的数据(每条数据1kb左右),数据可以保存一个月之久。
2、Hermes与Solr,ES在技术实现上也会有一些区别
Solr、ES在大索引上存在的问题:
一级跳跃表是完全Load在内存中的。这种方式需要消耗很多内存不说,首次打开索引的加载速度会特别慢。在SolrES中的索引是一直处于打开状态的,不会频繁的打开与关闭;这种模式会制约一台机器的索引数量与索引规模,通常一台机器固定负责某个业务的索引。
为了排序,将列的全部值Load到放到内存里。排序和统计(sum,max,min)的时候,是通过遍历倒排表,将某一列的全部值都Load到内存里,然后基于内存数据进行统计,即使一次查询只会用到其中的一条记录,也会将整列的全部值都Load到内存里,太浪费资源,首次查询的性能太差。数据规模受物理内存限制很大,索引规模上千万后OOM是常事。
索引存储在本地硬盘,恢复难.一旦机器损坏,数据即使没有丢失,一个几T的索引,仅仅数据copy时间就需要好几个小时才能搞定。
集群规模太小.支持Master/Slave模式,但是跟传统MySQL数据库一样,集群规模并没有特别大的(百台以内)。这种模式处理集群规模受限外,每次扩容的数据迁移将是一件非常痛苦的事情,数据迁移时间太久。
数据倾斜问题。倒排检索即使某个词语存在数据倾斜,因数据量比较小,也可以将全部的doc list都读取过来(比如说男、女),这个doc list会占用较大的内存进行Cache,当然在数据规模较小的情况下占用内存不是特别多,查询命中率很高,会提升检索速度,但是数据规模上来后,这里的内存问题越来越严重。
节点和数据规模受限。Merger Server只能是一个,制约了查询的节点数量;数据不能进行动态分区,数据规模上来后单个索引太大。
高并发导入的情况下, GC占用CPU太高,多线程并发性能上不去。AttributeSource使用了WeakHashMap来管理类的实例化,并使用了全局锁,无论加了多大的线程,导入性能上不去。AttributeSource与NumbericField,使用了大量的linkHashMap以及很多无用的对象,导致每一条记录都要在内存中创建很多无用的对象,造成了JVM要频繁的回收这些对象,CPU消耗过高。FieldCacheImpl使用的WeakHashMap有BUG,大数据的情况下有OOM的风险。单机导入性能在笔者的环境下(1kb的记录每台机器想突破2w/s 很难)
并不是说Solr与ES的这种方式不好,在数据规模较小的情况下,Solr的这种处理方式表现优越,并发性能较好,Cache利用率较高,事实证明在生产领域Solr和ES是非常稳定的,并且性能也很卓越;但是在数据规模较大,并且数据在频繁的实时导入的情况下,就需要进行一些优化。
Hermes在索引上的改进:
索引按需加载。大部分的索引处于关闭状态,只有真正用到索引才会去打开;一级跳跃表采用按需Load,并不会Load整个跳跃表,用来节省内存和提高打开索引的速度。Hermes经常会根据业务的不同动态的打开不同的索引,关闭那些不经常使用的索引,这样同样一台机器,可以被多种不同的业务所使用,机器利用率高。
排序和统计按需加载。排序和统计并不会使用数据的真实值,而是通过标签技术将大数据转换成占用内存很小的数据标签,占用内存是原先的几十分之一。
另外不会将这个列的全部值都Load到内存里,而是用到哪些数据Load哪些数据,依然是按需Load。不用了的数据会从内存里移除。
索引存储在HDFS中。理论上只要HDFS有空间,就可以不断的添加索引,索引规模不在严重受机器的物理内存和物理磁盘的限制。容灾和数据迁移容易得多。
采用Gaia进行进程管理(腾讯版的Yarn)。数据在HDFS中,集群规模和扩容都是一件很容易的事情,Gaia在腾讯集群规模已达万台)。
采用多条件组合跳跃降低数据倾斜。如果某个词语存在数据倾斜,则会与其他条件组合进行跳跃合并(参考doclist的skip list资料)。
多级Merger与自定义分区
GC上进行了一些优化自己进行内存管理,关键地方的内存对象的创建和释放java内部自己控制,减少GC的压力(类似Hbase的Block Buffer Cache)。不使用WeakHashMap和全局锁,WeakHashMap使用不当容易内存泄露,而且性能太差。用于分词的相关对象是共用的,减少反复的创建对象和释放对象。1kb大小的数据,在笔者的环境下,一台机器每秒能处理4~8W条记录.
Hermes的出现,并不是为了替代Solr、ES的,就像Hadoop的出现并不是为了干掉Oracle和MySQL一样。而是为了满足不同层面的需求。
Hermes应用案例
微信数据门户多维分析 (约370亿)
提供系统各个性能指标数据的实时分析。
信息安全部回溯项目(目前接入约2300亿)
基于全文检索查询、分析、统计并导出相关记录。
结果秒级返回。
Hermes性能数据
微信多维分析天数据370+亿,目前实时统计分析3s左右;
10亿记录数,10TB存储量,3台服务器(64G内存),8000+维度,查询分析耗时3s。
每天接入量2000+亿,最大宽表维度8000+,单机写入(包括数据预处理)性能8W/s。
本文地址:http://dfvalve.xrbh.cn/quote/6234.html
迅博思语资讯 http://dfvalve.xrbh.cn/ , 查看更多


